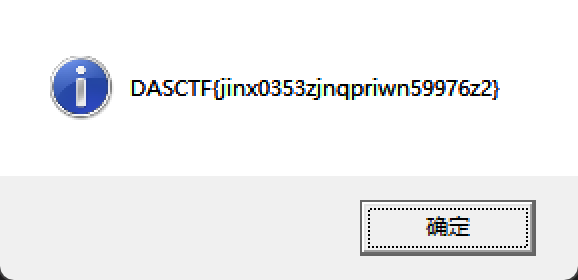
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
| import re, csv
from pathlib import Path
from datetime import datetime
from collections import Counter
# ---------------- 工具函数 ----------------
def is_valid_date_yyyymmdd(s: str) -> bool:
try:
datetime.strptime(s, "%Y%m%d")
return True
except Exception:
return False
def id_checksum_char(id17: str) -> str:
w = [7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2]
tab = ['1','0','X','9','8','7','6','5','4','3','2']
return tab[sum(int(a)*b for a,b in zip(id17, w)) % 11]
def valid_id(raw: str) -> bool:
core = re.sub(r'[-\s]', '', raw).upper()
if not re.fullmatch(r'\d{17}[0-9X]', core):
return False
if core[:6] == '000000':
return False
try:
prov = int(core[:2])
if not (11 <= prov <= 65):
return False
except:
return False
if core[14:17] == '000':
return False
b = core[6:14]
try:
bd = datetime.strptime(b, "%Y%m%d")
if bd.year < 1900 or bd > datetime.now():
return False
except:
return False
return core[-1] == id_checksum_char(core[:17])
def luhn_ok(num: str) -> bool:
num = re.sub(r'[\s-]', '', num)
if not (16 <= len(num) <= 19 and num.isdigit()):
return False
ds = [int(x) for x in num[::-1]]
s = 0
for i, d in enumerate(ds):
if i % 2:
d = d * 2 - 9 if d * 2 > 9 else d * 2
s += d
return s % 10 == 0
def valid_ip(ip: str) -> bool:
ip = ip.replace(".", ".").replace("。", ".")
parts = ip.split('.')
if len(parts) != 4:
return False
try:
for p in parts:
if not (0 <= int(p) <= 255):
return False
if len(p) > 1 and p.startswith('0'):
return False
return True
except Exception:
return False
# ---------------- 常量集合 ----------------
PHONE_PREFIX3 = {
'130','131','132','133','134','135','136','137','138','139',
'140','145','146','149','150','151','152','153','155','156',
'166','167','171','172','173','174','175','176','177','178',
'180','181','182','183','184','185','186','187','188','189',
'190','191','193','195','196','198','199','147','148'
}
prefix_alt = "(?:" + "|".join(sorted(PHONE_PREFIX3)) + ")"
# ---------------- 正则模式 ----------------
PATTERNS = {
"idcard": re.compile(r'(?<!\d)(?:\d{17}[0-9Xx]|\d{6}[-\s]+\d{8}[-\s]+\d{3}[0-9Xx])(?!\d)'),
"phone": re.compile(rf'''
(?<!\d)
(?:\+86\s*|\(\+86\)\s*)?
({prefix_alt})
(?:
\d{{8}} # 连续 11 位(已含前三位)
| [-\s]\d{{4}}[-\s]\d{{4}} # 严格 3-4-4:恰好两处分隔
)
(?!\d)
''', re.VERBOSE),
"bankcard": re.compile(
r'(?<!\d)(?:'
r'(?:[1-9]\d{15,18})'
r')(?!\d)'
),
"ip": re.compile(r'(?<!\d)(?:\d{1,3}\.){3}\d{1,3}(?!\d)'),
"mac": re.compile(r'[0-9A-Fa-f]{2}(?::[0-9A-Fa-f]{2}){5}')
}
# ---------------- 核心识别函数 ----------------
def detect_sensitive_data(text: str):
out, seen = [], set()
def push(cat, val, pos):
if (cat, val) not in seen:
seen.add((cat, val))
out.append((pos, cat, val.strip()))
for m in PATTERNS["idcard"].finditer(text):
s = m.group(0)
if valid_id(s): push("idcard", s, m.start())
for m in PATTERNS["phone"].finditer(text):
s = m.group(0)
digits = re.sub(r"\D", "", s)
if digits.startswith("86") and len(digits) > 11:
digits = digits[2:]
if len(digits) == 11 and digits[:3] in PHONE_PREFIX3:
mid = digits[3:7]
if not re.match(r"(19|20)\d{2}", mid):
push("phone", s.strip(), m.start())
for m in PATTERNS["bankcard"].finditer(text):
s = m.group(0)
if luhn_ok(s):
if not re.match(r'\d{6}(19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])', s):
push("bankcard", s, m.start())
for m in PATTERNS["ip"].finditer(text):
s = m.group(0)
if valid_ip(s): push("ip", s, m.start())
for m in PATTERNS["mac"].finditer(text):
s = m.group(0).lower()
if all(re.fullmatch(r"[0-9A-Fa-f]{2}", seg) for seg in s.split(":")):
push("mac", s.lower(), m.start())
# ✳️ 改动关键处:分类排序(不按出现顺序,而按类别块排序)
category_order = ["idcard", "phone", "bankcard", "ip", "mac"]
out.sort(key=lambda x: (category_order.index(x[1]), x[0]))
return out
# ---------------- 输出 ----------------
def write_to_csv(out_data, output_path: Path):
with output_path.open("w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(["category", "value"])
for _, cat, val in out_data:
writer.writerow([cat, val])
# ---------------- 主程序 ----------------
def main():
DATA_PATH = Path("data.txt")
OUT_PATH = Path("result_plus_grouped.csv")
text = DATA_PATH.read_text(encoding="utf-8", errors="ignore")
results = detect_sensitive_data(text)
write_to_csv(results, OUT_PATH)
cnt = Counter(c for _, c, _ in results)
print(f"✅ 输出文件: {OUT_PATH}")
print("📊 统计:", dict(cnt))
if __name__ == "__main__":
main()
|